




La digitalisation des activités est, à de nombreux titres, une avancée majeure qu’IFPEN a entrepris de déployer au bénéfice de sa R&I. Elle consiste à intégrer des technologies numériques innovantes pour améliorer l'efficacité, la précision et la productivité de nos actions. Elle consiste également à intégrer des applications prometteuses en intelligence artificielle (IA) générative.
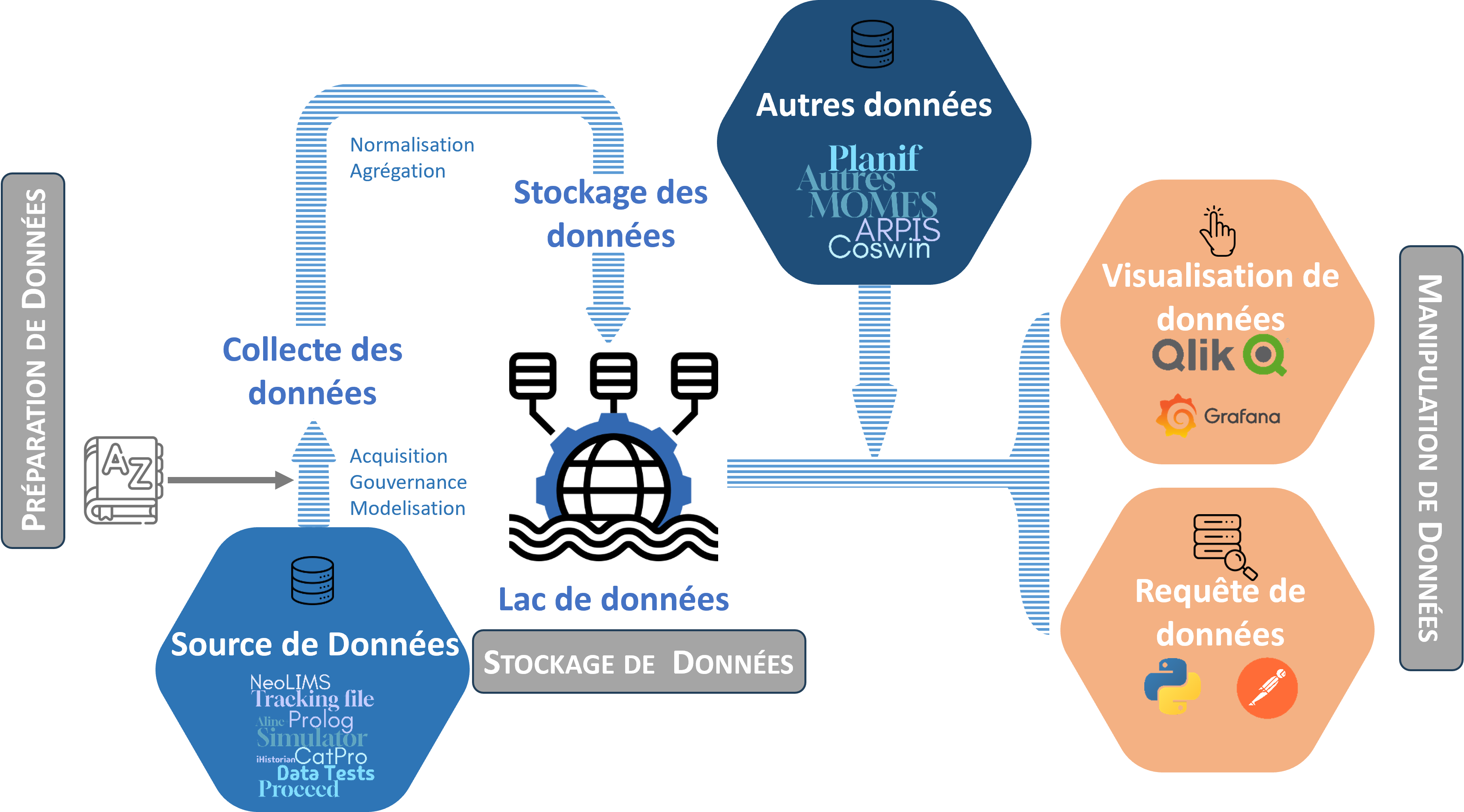
Dans le domaine des unités-pilotes, le projet DataUP, conduit par IFPEN, a pour vocation de structurer et valoriser la donnée expérimentale et de la rendre accessible par tous. Le processus qu’il met en œuvre repose sur trois étapes clés (Figure 1) : la préparation des données, leur stockage puis leur exploitation. Lors de la préparation, les données sont collectées à partir des diverses sources puis passent par une étape de gouvernance1. Ces données sont ensuite normalisées et agrégées puis centralisées dans un "data lake", garantissant ainsi leur accessibilité et leur pérennité. Les utilisateurs peuvent alors utiliser ces données via des outils de visualisation ou des requêtes personnalisées.
1 La gouvernance des données est l'ensemble des pratiques mises en œuvre pour assurer la sécurité, la confidentialité, l'exactitude, la disponibilité et l'exploitabilité des données.
Les bénéfices de cette nouvelle gestion des données sont multiples. En premier lieu, grâce à leur centralisation, une accessibilité accrue des données expérimentales facilite leur consultation et leur exploitation. Ceci permet également des prises de décisions éclairées, en vertu d’analyses reposant sur des données fiables et validées. Le suivi et l’utilisation des résultats sont par ailleurs facilités par le recours à des outils de visualisation.
Par ailleurs, la mise en place d’un référentiel des grandeurs assure une homogénéité des définitions entre les différentes équipes de recherche. Enfin, la séparation claire entre les différents outils (de structuration des données, de visualisation et de calcul) permet de mettre à jour ou d'améliorer chaque outil indépendamment des autres, sans compromettre l'ensemble du système. De plus, les données ne sont pas modifiées à la source, assurant l’intégrité des données originales pour les usages futurs.
Grâce à la digitalisation, c’est la capacité de recherche et d’innovation qui sort gagnante. Un exemple est fourni par le logiciel RING dont l’objet est de gérer efficacement le workflow de production des données expérimentales issues de divers procédés de génie chimique. Il représente une évolution majeure par rapport au logiciel préexistant, en intégrant des fonctionnalités avancées pour l’acquisition et l’utilisation des résultats. En tant que source primaire de données, il occupe une place centrale dans le système d’information d’IFPEN.
RING a trois fonctionnalités clés : l’agrégation des données, la réalisation de calculs et l’exploitation des données.
L’agrégation consiste à trier et prioriser les données expérimentales qui seront enrichies par calcul. Cet enrichissement consiste en des vérifications, comme via des bilans matière, ou en la génération d’indicateurs de performance, tel qu’un taux de conversion pour un procédé réactionnel.
Tous ces calculs sont standardisés et s’appuient sur diverses sources, telles que les mesures issues des capteurs des unités pilotes, les analyses en ligne ou délocalisées ou encore les données catalytiques.
Enfin, l’exploitation des données permet d’extraire des points expérimentaux servant à effectuer des recherches multicritères ou de produire des données destinées à la modélisation cinétique.
Comme revendiqué, les bénéfices liés à la mise en place de RING sont la capitalisation et la pérennisation des données expérimentales ainsi que des « calculs métiers » associés, tout en simplifiant l’accès à l’ensemble de ces données.
Deux principaux outils sont mis à disposition des utilisateurs pour la visualisation des données. L’un offre un accès rapide aux données provenant de différentes sources et facilite leur extraction pour la modélisation. Les avantages incluent l’identification de conditions opératoires et de formulation pertinentes, ainsi que la recherche d’anomalies. L’autre permet de visualiser les données du type « séries temporelles » telles que les capteurs des unités pilotes ou les données d’analyse en ligne. Cet outil permet le suivi quotidien des unités pilotes ainsi que la compréhension des incidents.
Au-delà de l’exploitation des résultats des procédés intégrés dans DataUP, ces outils sont des aides précieuses pour la comparaison et l’exploitation de tests à grande échelle. Par ailleurs, les outils de visualisation de données sont utiles bien au-delà du cadre visé. Ainsi, une application développée pour le suivi automatisé de la consommation des utilités a permis un gain de temps significatif pour son responsable.
Enfin, la structuration et la mise à disposition des données expérimentales, permises par ces développements, offrent de nombreuses perspectives, dont certaines déjà exploitées, pour déployer des solutions fondées sur l’intelligence artificielle.
Contact scientifique: Alice Faure