




Thèse de Claire Bizon Monroc : « Apprentissage par renforcement multi-agent pour le contrôle dynamique de parcs éoliens »
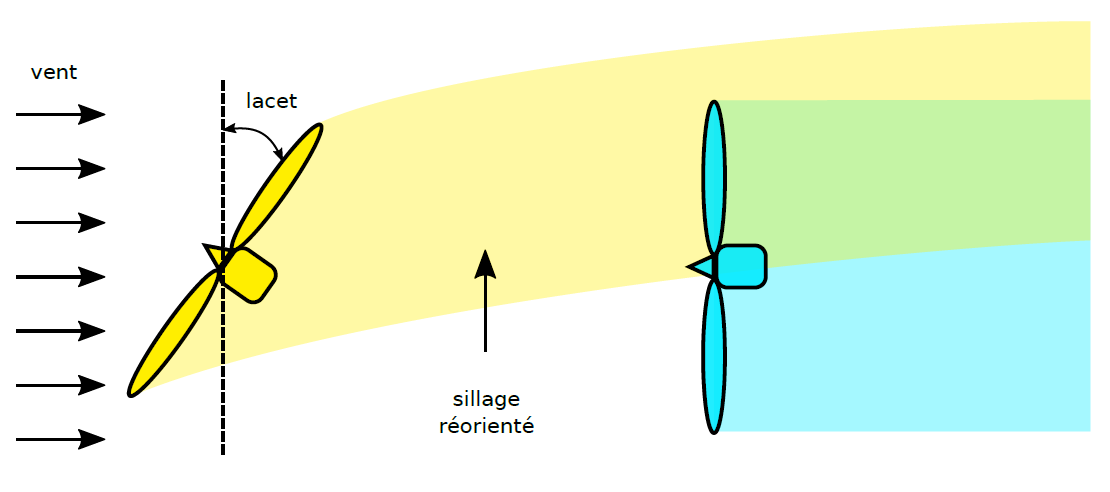
Lorsque des éoliennes sont regroupées en parc, il arrive que, pour des conditions de vent données, elles interagissent entre elles par ce que l'on appelle l'effet de sillage. Lorsqu'une éolienne capte l'énergie cinétique du vent, par conservation de l'énergie, le flux de vent en aval subit un déficit de vitesse et une augmentation de sa turbulence. Les éoliennes se trouvant dans ce sillage voient donc leur production électrique baisser significativement, tout en subissant une fatigue mécanique accrue. Ces effets de sillage (Figure 1) provoquent des pertes de production annuelles pouvant atteindre 20%.
Il est possible d’exercer une influence sur les sillages en pilotant certains actionneurs de l'éolienne. Parmi ceux-ci, le lacet, défini comme l'angle entre la direction du vent et le plan du rotor, permet de dévier le sillage et donc de fournir potentiellement plus d'énergie à l'éolienne affectée par celui-ci (Figure 2). Cependant, pour maximiser leur puissance individuelle, les éoliennes se positionnent de manière orthogonale à la direction du vent incident (c'est-à-dire que l'angle de lacet est nul), et diminuer ou augmenter la valeur de cet angle entraîne une perte de puissance pour l'éolienne concernée. Il s'agit donc de passer d'une stratégie de contrôle individuelle, à une stratégie collective visant à maximiser la puissance fournie à l'échelle du parc éolien.

Trouver à l’échelle du parc la combinaison de lacets qui maximise sa production est un problème d'optimisation difficile. Les stratégies de contrôle classiques nécessitent en effet la modélisation d'interactions aérodynamiques complexes entre les turbines. Or, les modèles sont soit trop rudimentaires pour conduire à des solutions optimales sur le terrain soit trop complexes pour permettre des simulations à l'échelle du parc, lorsque le nombre de turbines augmente. Une alternative consiste à exploiter des mesures collectées en temps réel dans le parc éolien : on cherche alors à concevoir des méthodes capables d’apprendre la combinaison optimale de lacets en observant uniquement la production électrique totale.
Cette stratégie d’optimisation se heurte cependant à plusieurs défis :
- en premier lieu, les temps de propagation du sillage qui créent un délai entre un changement de lacet et le moment où son impact sur la production du parc peut être observé ;
- ensuite, la difficulté à mesurer la contribution exacte à la production totale du changement de lacet de chacune des turbines ;
- enfin, la complexification de ces deux problèmes - temps de propagation et attribution de la récompense - lorsque le nombre d'éoliennes augmente et que la taille de l'espace de recherche explose.
Dans cette thèse, le contrôle des parcs éoliens a été formulé comme un problème d’apprentissage par renforcement multi-agent (MARL). Contrairement aux méthodes de contrôles classique basées sur des modèles, l’apprentissage par renforcement (RL) est une méthode qui n’a pas besoin de connaissance apriori sur les modèles physiques. Un agent RL apprend à prendre de meilleures décisions par essai-erreur en interagissant avec son environnement. L’approche MARL décentralisée proposée dans cette thèse consiste à coordonner plusieurs agents RL – chaque agent contrôlant une turbine – pour maximiser la production totale du parc.
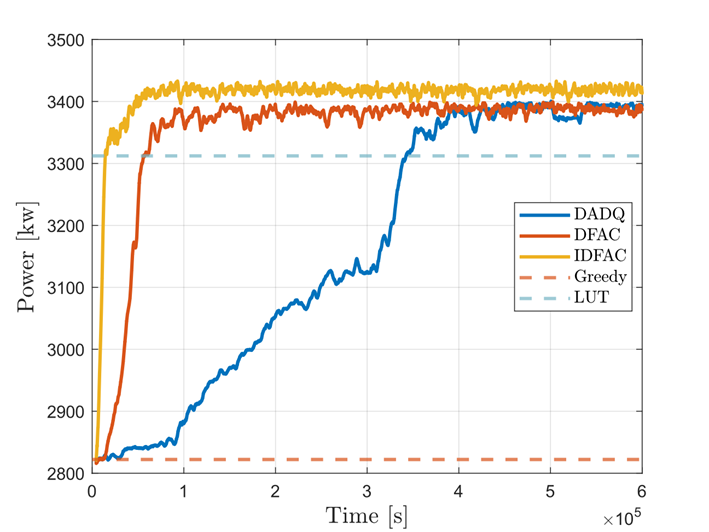
Nous avons proposé plusieurs algorithmes de MARL décentralisés [1,2,3]. Ces algorithmes sont capables de prendre en compte la propagation dynamique des sillages dans les parcs, et ils sont faciles à appliquer à un grand nombre de turbines grâce à leur nature multi-agent décentralisée. Ces algorithmes ont été évalués dans des simulateurs de référence dans le domaine éolien, pour des parcs comptant de 3 à 36 éoliennes. Dans tous les cas testés, ils permettent une augmentation significative de la production pouvant atteindre plus de 20 % par rapport à la stratégie classique (dite « Greedy ») où toutes les éoliennes sont orientées face au vent (Figure 3).
Pour faciliter les recherches futures dans l'application des méthodes d'apprentissage par renforcement pour le contrôle de parcs éoliens, nous avons également développé une bibliothèque logicielle open-source appelée WFCRL1[4]. Celle-ci permet un interfaçage facile des outils de contrôle communément utilisés par la communauté de l'apprentissage par renforcement, avec les simulateurs de référence de parcs éoliens FLORIS et FAST.Farm2.
Enfin, d'un point de vue théorique, nous avons montré la convergence d’un algorithme multi-échelle dans le cadre de MARL où la dynamique des agents peut être représentée par un DAG (graphe acrylique orienté) [5]. Ce résultat donne une compréhension théorique des résultats expérimentaux de la thèse.
Ces résultats suggèrent que nos algorithmes de RL pourraient apprendre en ligne sur des parcs éoliens réels. Actuellement, nous poursuivons nos travaux afin d'améliorer davantage le temps de convergence et la robustesse face aux conditions de vent. Nous travaillons également à étendre nos algorithmes afin de prendre en compte les charges de fatigue (induites par les sillages et les turbulences), ainsi que pour permettre aux parcs éoliens de fournir des services au réseau électrique, par exemple en suivant un signal de puissance demandé par un gestionnaire de réseau électrique.
1 https://github.com/ifpen/wfcrl-env et https://github.com/ifpen/wfcrl-benchmark
2 Tous deux développés par le Laboratoire National des Energies Renouvelables américain (NREL)
Références :
- Bizon Monroc, C., Bouba, E., Bušić, A., Dubuc, D., and Zhu, J. (2022). Delay-aware decentralized q-learning for wind farm control. In 2022 IEEE 61st Conference on Decision and Control (CDC). IEEE.
>> DOI : http://dx.doi.org/10.1109/CDC51059.2022.9992646
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2023). Actor critic agents for wind farm control. In 2023 American Control Conference (ACC). IEEE.
>> DOI : http://dx.doi.org/10.23919/ACC55779.2023.10156453
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). Towards fine tuning wake steering policies in the field: an imitation-based approach. TORQUE 2024. IOP Publishing.
>> DOI : http://dx.doi.org/10.1088/1742-6596/2767/3/032017
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). WFCRL: A Multi-Agent Reinforcement Learning Benchmark for Wind Farm Control, NeurIPS 2024 Datasets and Benchmarks Track.
>> DOI : http://dx.doi.org/10.48550/arXiv.2501.13592
- (under review at SIMODS, preliminary version presented at ARLET Workshop, ICML 2024) Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). Multi-agent reinforcement learning for partially observable cooperative systems with acyclic dependence structure.
>> https://hal.science/hal-04560319/document
Contacts scientifiques : Jiamin Zhu, Donatien Dubuc