




Les données de spectroscopie proche infrarouge (SPIR1) font l’objet de traitements mathématiques, via des approches chimiométriques2 en utilisant généralement un modèle de type Partial Least Squares (PLS). Cette méthodologie linéaire cherche à établir une relation statistique, représentée par la covariance maximale, entre une variable explicative X et la variable expliquée y. Elle a fait ses preuves à IFPEN pour prédire les propriétés de produits pétroliers et, depuis quelques années, elle a suivi le virage des nouvelles technologies de l'énergie (NTE) en s’appliquant à des domaines comme les bio-carburants ou le recyclage chimique des plastiques.
L’approche en elle-même repose notamment sur des opérations de pré-traitement du signal destinées à corriger les artefacts analytiques qui impactent la pertinence des modèles issus de l’exploitation des données expérimentales. Cependant, dans un domaine en perpétuelle évolution qui impose la mise à jour plus régulière des modèles, cette solution n’est plus considérée comme satisfaisante.
L’apprentissage profond, alternative prometteuse pour le développement de modèles issus de l’expérience, est actuellement abordé dans le cadre d’un travail de thèse3. Dans cette approche, un réseau de neurones extrait l’information à partir des données sans qu’il soit nécessaire de préciser explicitement comment le faire. Un calcul d’erreur4 entre la prédiction du modèle et la valeur attendue pour la variable expliquée permet l’optimisation des paramètres internes du réseau de neurones. Il s’agit là d’un changement de paradigme complet par rapport à la chimiométrie pour laquelle il est nécessaire de développer un plan d’expérience et de tester différentes combinaisons de traitement de signal.
Un travail mené à IFPEN s’est intéressé aux réseaux convolutionnels profonds et en particulier à développer le sien propre, « Inception for Petroleum Analysis » (IPA), en vue de mieux répondre aux besoins quotidiens en matière d'analyse SPIR [1]. Il est inspiré de l’état de l’art en apprentissage profond pour la vision assistée par ordinateur et basé sur plusieurs blocs de calcul, dont l’architecture est présentée sur la Figure 1.
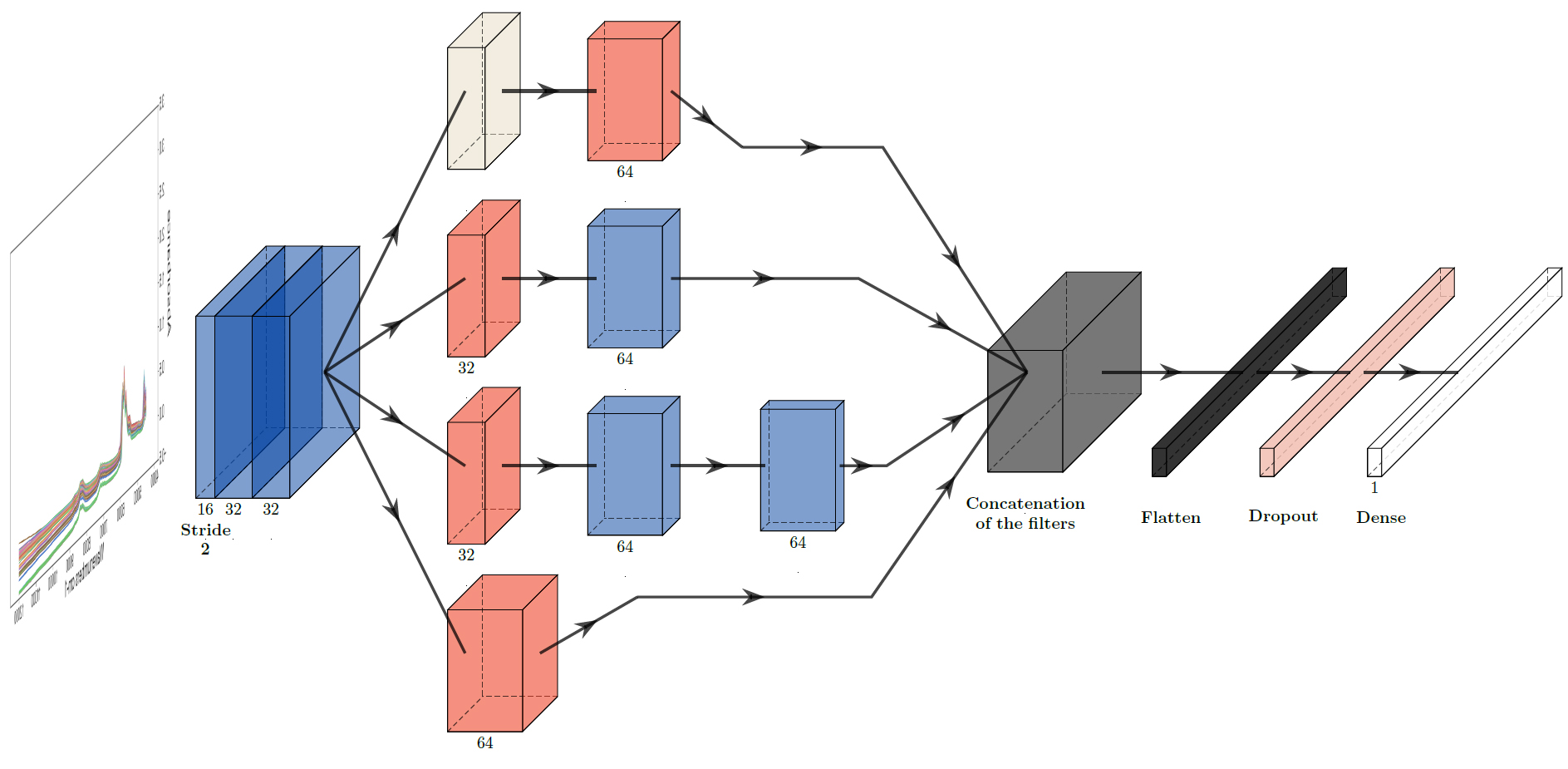
Par comparaison avec un modèle chimiométrique traditionnel (PLS) et avec le modèle d’apprentissage profond DeepSpectra [2], pris comme référence, le modèle IPA a été testé sur sa capacité à prédire le nombre de cétane5 des distillats moyens produits à partir de divers procédés industriels. Tous trois ont d’abord été entraînés sur un jeu de 174 spectres SPIR, enregistrés dans la gamme spectrale 4000-12000 cm-1 puis testés pour validation sur une autre base de 75 spectres. Dans ces bases, le nombre de cétane variait de 19.0 à 71.1, avec pour moyenne 43.3 et un écart type de 11.1. La gamme spectrale a été réduite dans un premier temps pour supprimer les bandes PIR entre 4000-4500 cm-1, saturées et affectées par des problèmes de non-linéarité. Le modèle PLS a nécessité une étape de pré-traitement du signal avant calibration comprenant une correction de la ligne de base, contrairement à la calibration du modèle IPA qui se fait directement sur des données sans pré-traitement.
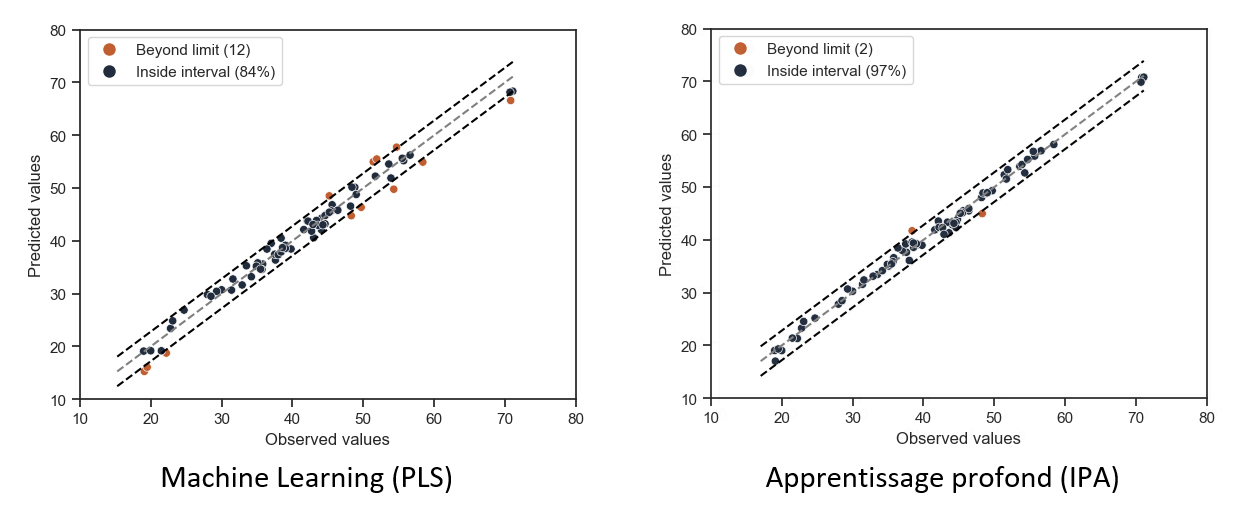
La qualité des modèles est généralement évaluée à l’aide de plusieurs distances, notamment la racine carrée de l’erreur quadratique moyenne, calculée entre les prédictions du modèle et les valeurs mesurées. Sur la gamme spectrale réduite, entre 4500-12000 cm-1, le modèle IPA présente une erreur inférieure de 40 % par rapport au modèle PLS, et est 20 % plus précis que le modèle d'apprentissage profond DeepSpectra. De plus, dans deux zones de nombre de cétane peu renseignées en termes de calibration6, une différence importante de prédiction entre les différents modèles a été observée (Figure 2) : il s’agit des parties extrêmes du diagramme de parité de la base de validation, où IPA propose des prédictions pertinentes alors que le modèle PLS manque de précision (tout comme pour DeepSpectra, non montré ici). Enfin, sur le même ensemble de données, en prenant la gamme spectrale complète 4000-12000 cm-1, IPA est 50 % plus précis que la PLS et 21 % plus précis que DeepSpectra.
Les performances supérieures du modèle IPA montrent qu’il est en mesure de capturer davantage d’informations pertinentes que les modèles PLS et DeepSpectra, plus particulièrement dans la gamme spectrale complète et ce, sans être perturbé par la partie saturée. De même, dans les plages de valeurs extrêmes prises en compte, IPA est resté performant pour généraliser l'information à une large gamme de valeur de la propriété prédite, à la différence des modèles PLS et DeepSpectra.
1- En anglais : Near Infrared Spectroscopy (NIRS).
2- La chimiométrie est l'application d'outils mathématiques, en particulier statistiques, pour obtenir le maximum d'informations à partir de données issues des analyses physico-chimiques.
3- Thèse de F. Haffner, Apprentissage profond et proche infrarouge pour intensifier l'usage des méthodes spectroscopiques.
4- Reposant sur une fonction de perte.
5- Nombre permettant d'évaluer précisément l'aptitude d'un gazole à s'auto-enflammer.
6- Nombres de cétane de 18 à 20 et de 70 à 72.
Références :
- F. HAFFNER, M. LACOUE-NEGRE, A. PIRAYRE, D. GONÇALVES, J. GORNAY and M. MOREAUD, IPA: A deep CNN based on Inception for Petroleum Analysis, Fuel, Publication soumise.
- X. ZHANG et al., DeepSpectra: An end-to-end deep learning approach for quantitative spectral analysis, Analytica chimica acta, 2019
>> DOI: 10.1016/j.aca.2019.01.002
Contacts scientifiques : Maxime Moreaud (deep learning) et marion.lacoue-negre@ifpen.fr (proche infrarouge, chimiométrie)
Vous serez aussi intéressé par
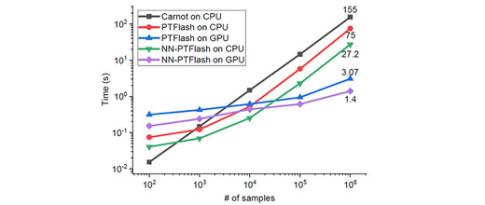
La thermodynamique fait son apprentissage… profond
La simulation du transport réactif de fluides a de multiples applications - écoulements en milieu poreux, combustion, génie des procédés - et requiert des calculs d’équilibre thermodynamique (aussi appelés calculs « flash »). Cependant, ces calculs peuvent avoir des durées importantes et, comme ils interviennent en grand nombre dans les simulations réalisées, ils limitent en pratique ces dernières à des systèmes contenant peu d’espèces chimiques ou à des échelles de temps et d’espace restreintes...
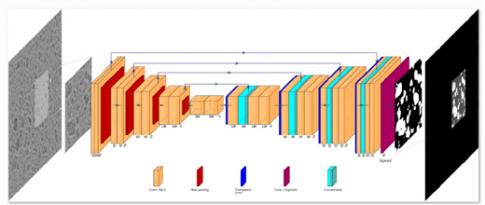
Segmentation sémantique par apprentissage profond en sciences des matériaux
La segmentation sémantique réalisée sur des images de microscopie est une opération de traitement effectuée en vue de quantifier la porosité d’un matériau et son hétérogénéité. Elle vise à affecter une classe d’appartenance (niveau d’hétérogénéité de la porosité) à chaque pixel de l’image. Cependant elle est très difficile sur certains matériaux (comme les alumines employées pour la catalyse), voire impossible par une approche classique de traitement d’image, car les différences de porosité sont caractérisées par des contrastes faibles et des variations de texture complexes. Un moyen de dépasser cette limitation est d’aborder par apprentissage profond la segmentation sémantique, en recourant à un réseau de neurones convolutifs.
L’apprentissage par transfert de connaissance pour l’optimisation des procédés
IFPEN est un leader mondial dans le développement de catalyseurs et de procédés pour la production de carburants propres. Pour que ces procédés soient eux-mêmes éco-efficients, il est nécessaire d’optimiser le couplage des catalyseurs avec les conditions opératoires, en fonction des charges utilisées et des spécifications recherchées pour les produits raffinés. Il est dès lors utile de pouvoir s’appuyer sur des modèles prédictifs quant aux performances atteintes et le recours à l’apprentissage (Machine learning) est une option intéressante dans ce cas...